
Heute am Aschermittwoch beginnt mal wieder die Fastenzeit. Und der Kampf gegen die Kilos die die Waage unverschämterweise immer zu hoch anzeigt. Ich habe neben meiner Blutdruckstatistik auch eine über das Gewicht, weil ich mich ja seit Jahren jeden Morgen brav auf die Waage stelle und das dann wie es sich für einen Data-Scientist gehört auch entsprechend auswerte.
Es kommt mal wieder R zum Einsatz und das Datenfile ist jetzt noch einfacher gestrickt als bei den Blutdruckwerten:
Datum Zeit Gewicht 19.01.10 05:45 115.9 20.01.10 05:45 115.9 21.01.10 05:45 115.2
Der Sourcecode des R-Skriptes ähnelt erst mal sehr stark dem von der Blutdruckstatistik was ja dank Copy&Paste kein Wunder ist.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Rework of th weight stats library(ggplot2) # for all the graphics we use ggplot library(plyr) # ddply function call needs this library(gdata) # for date functions # extract the last num lines from the dataset get_latest <- function(data, num) { rows <- nrow(data) cols <- ncol(data) start <- rows - num +1; return( data[start:rows,0:cols] ) } #read the weight data from the file wt_data <- read.table("gewicht.txt", header=TRUE, sep=" ") wt_data$Timestamp <- strptime(paste(wt_data$Datum, wt_data$Zeit), "%d.%m.%y %H:%M") wt_data <- subset(wt_data, select=c(-Datum, -Zeit)) |
Nach diesen Zeilen haben wir in dem Dataframe wt_data also den Zeitstempel und das dazugehörende Gewicht drin. In den nächsten beiden Zeilen erweitern wir den Dataframe um Faktoren wie Monate oder Wochen.
|
20 21 |
wt_data$month <- format(wt_data$Timestamp, "%Y-%m") wt_data$week <- format(wt_data$Timestamp, "%Y-%W") |
Damit haben wir zu jedem Datum dann eine Information, zu welchem Monat oder welche Woche im Jahr es gehört. Das brauchen wir für die Auswertung. Zunächst schauen wir uns aber mal die Gewichtskurve der letzen dreißig Messungen an.
|
22 23 24 25 26 27 |
# plot a graph for the latest 30 days wt_latest <- get_latest(wt_data, 30) weight_plot_latest <- ggplot(wt_latest, aes(x=Timestamp, y=Gewicht)) + geom_line() + geom_point() + xlab("Datum") + labs(title="Entwicklung über die letzten 30 Tage") |
Damit wird dann eine solche Kurve erzeugt: 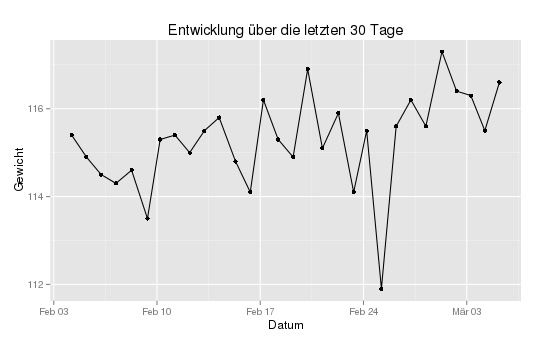 Das ist ziemlich zackig und hängt natürlich auch damit zusammen, dass moderne Waagen auf 100g genau (oder auch nicht, wir hatten da eine die schwankte um +- 5kg bei mehrmaligem Wiegen) anzeigen und die Werte also ungeglättet drin sind. Darum ist es eigentlich auch interessanter, wenn man ich einfach mal den ganzen Zeitraum anschaut. Bei mir wären das aktuel 1363 Messwerte, wenn ich die als Kurve in eine Graphik von 540 Pixel breite plotte sieht man exakt nichts außer viel schwarz. Also müssen wir mal die Kurve so aufbereiten, dass wir z.B. einfach für jeden Monat (deshalb vorher die Monatsstempel im Dataframe) einen Mittelwert bilden.
Das ist ziemlich zackig und hängt natürlich auch damit zusammen, dass moderne Waagen auf 100g genau (oder auch nicht, wir hatten da eine die schwankte um +- 5kg bei mehrmaligem Wiegen) anzeigen und die Werte also ungeglättet drin sind. Darum ist es eigentlich auch interessanter, wenn man ich einfach mal den ganzen Zeitraum anschaut. Bei mir wären das aktuel 1363 Messwerte, wenn ich die als Kurve in eine Graphik von 540 Pixel breite plotte sieht man exakt nichts außer viel schwarz. Also müssen wir mal die Kurve so aufbereiten, dass wir z.B. einfach für jeden Monat (deshalb vorher die Monatsstempel im Dataframe) einen Mittelwert bilden.
|
28 29 30 31 32 33 34 35 |
# plot the all time curve since recordings began curve_all <- ddply(wt_data,"month", summarize, mean_weight=mean(Gewicht)) curve_all$x <- as.numeric(rownames(curve_all))-1 # from 0..n months weight_plot_all <- ggplot(curve_all, aes(x=x,y=mean_weight)) + geom_point() + geom_line(color="red", alpha=0.25) + xlab("Monate seit Aufzeichnungsstart") + ylab("durchschnittliches Gewicht") + labs(title="Durchschnittswerte aller aufgezeichneten Monate") |
Die interessante Funktion hier ist „ddply“ das den Dataframe nimmt und mittels „summarize“ den Mittlerwert über alle Gewichtseinträge ermittelt die in der Spalte „month“ (unser Monatsstempel) den gleichen Wert haben. Den daraus resultierenden Dataframe können wir dann sehr einfach plotten:
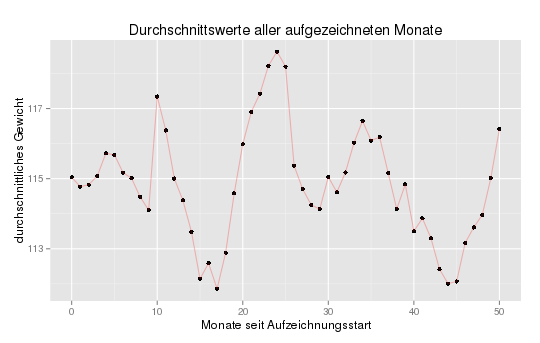
Hier sieht man sehr schön den sogenannten Jojo-Effekt, man nimmt ab und irgendwann später kommen die Kilos wieder, manchmal sogar mit Verstärkung.
Der letzte Plot betrachtet dann die letzen 12 Monate.
|
36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# have a close look at the latest 12 months now <- Sys.Date() year <- as.numeric(getYear(now)) month <- as.numeric(getMonth(now))-11 if (month < 1) { year=year-1 month=12+month } startdate <- as.POSIXlt(ISOdate(year,month,1,hour=1)) # select from 12 months ago wt_range <- subset(wt_data, Timestamp >= startdate) weight_plot_year <- ggplot(wt_range, aes(x=factor(month),y=Gewicht)) + geom_boxplot() + stat_summary(fun.y="mean", geom="point", color="red", size=2) + xlab("Monat") + labs(title="Rückblick auf die letzten 12 Monate") |
Hier berechnen wir erst mal den Startmonat der ein Jahr vom aktuellen Datum zurückliegt. Dann holen wir uns alle Daten aus dem Dataframe ab dem 1. dieses Startmonats in einen eigenen Dataframe (wt_range). Den plotten wir dann als Boxplot. Boxplots zeigen die Verteilung der Messwerte an, der schwarze Strich ist der Median, die Box definiert die 25% und 75% Qauntile. Die Ausreißer sind als schwarze Punkte dargestellt, der Mittlerwert des jeweiligen Monats ist durch einen roten Punkt repräsentiert. Der Plot sieht dann so aus:
 Damit ist das Dilemma ausreichend gut dokumentiert und der Kampf gegen die Kilos geht weiter. Den Sourcecode für das R-Skript könnt ihr wie immer auch herunterladen.
Damit ist das Dilemma ausreichend gut dokumentiert und der Kampf gegen die Kilos geht weiter. Den Sourcecode für das R-Skript könnt ihr wie immer auch herunterladen.
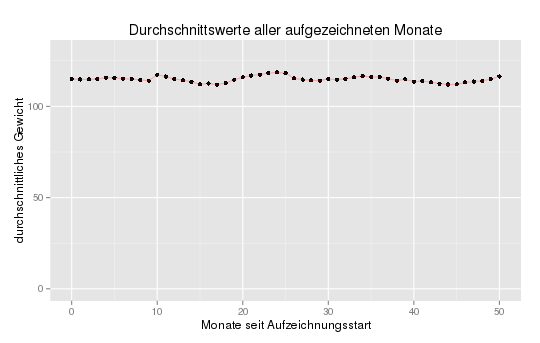
Update: Wie Carsten in den Kommentaren richtig geschrieben hat sind die Graphen natürlich in gewisser Weise „Lüge mit Statistik“ da der angezeigte Wertebereich gerade mal die Spanne vom kleinsten bis zum größten Wert umfasst. Das ist ungefähr so wie wenn ich mit einem Mikroskop auf eine glatte Oberfläche gucke, die sieht bei entsprechender Vergrößerung auch aus wie ein Gebirgszug.
Zum Glück ist das in R ja sehr leicht zu ändern, wenn ich den Plot mit „+ ylim(0,130)“ aufrufe, dann läuft die Y-Achse tatsächlich von 0 bis 130. Und dann sieht der Verlauf der Jojo-Kurve natürlich viel „flacher“ aus:
[ratings]
Vielleicht ein kleiner Tip für die Psyche (wenn’s nötig ist): Die Schwankungsbreite Deiner Messungen liegt im Bereich von 2 kg (bzw. 4 kg). Das ist das Schöne an der graphischen Aufbereitung von Daten, wenn die Skalen sehr stark gespreizt sind, dann wirken sich bereits +/- 100 g Änderungen optisch sehr stark aus. Daher siehst Du auch die großen Ausschläge, die mal beunruhigender, mal euphorisierender sich auswirken können. Wenn die Gewichtsaufzeichnung einem Ziel folgt (bspw. Reduzierung um 10 kg innerhalb eines Jahres), sollte die Skalierung entsprechend angepaßt werden (also bespielsweise zwischen 85 und 120 kg). Dann lassen sich die Tendenzen besser einschätzen und bewerten. Wenn es nur zur Dokumentation dient, ist’s eigentlich egal.
Letztlich aber ein netter Exkurs in R, von dessen Mächtigkeit ich schon viel gelesen habe, mich aber noch nicht getraut habe, es selbst auszuprobieren (Zeit und Muße fehlen dazu auch).
Richtig. Ich habe mal den Artikel aktualisiert und einen Plot eingefügt der von 0-130 auf der y-Achse geht.